
Companies maximize AI performance with Solidigm SSDs
As artificial intelligence (AI) workloads grow in complexity and scale, the need for balanced, high-performance infrastructures becomes more critical than ever. At Quanta Cloud Technology (QCT), we’re committed to pushing the boundaries of AI system design. In collaboration with Solidigm, we’ve conducted a comprehensive study using MLPerf benchmarks to evaluate how different SSD technologies impact AI performance across inference, training, and storage workloads.
Using MLPerf Inference v4.1, Training v4.1, and Storage v2.0, we tested three Solidigm SSDs, to assess AI system performance across diverse hardware configurations, offering critical insights into optimizing workloads. (Note: Not all these results are verified, reviewed and/or authenticated by the MLCommons Association.)
- Solidigm™ D7-PS1010 (PCIe Gen5) – High-performance, low-latency
- Solidigm™ D5-P5336 (PCIe Gen4) – High-capacity, cost-efficient
- Solidigm™ D3-S4520 (SATA) – Legacy-compatible, entry-level
These SSDs were deployed across two of our QCT server platforms:
- QuantaGrid D74H-7U – Optimized for high-density GPU workloads, this is a 7U high-density server supporting up to 32 GPUs, PCIe Gen5, and advanced cooling for large-scale AI training and HPC workloads.
The D74H-7U was configured with both Solidigm D7-PS1010 and D5-P5336 NVMe SSDs for MLPerf Inference and Training benchmarking.

Figure 1. QuantaGrid D74H-7U
- QuantaGrid D54U-3U – Delivering balanced compute and storage performance, this 3U server supports up to 8 GPUs, flexible NVMe/SATA storage, and PCIe Gen4 for versatile AI training, inference, and data analytics. The D54U-3U used all three Solidigm SSDs for inference, training, and storage testing.

Figure 2. QuantaGrid D54U-3U
Test Configuration
MLPerf Inference v4.1
Given that inference workloads primarily rely on memory and GPU performance, the objective was to determine whether increased disk count had any measurable impact on performance. (Note: Speed up is normalized to the 1-disk configuration (=1.00) across these tests.)
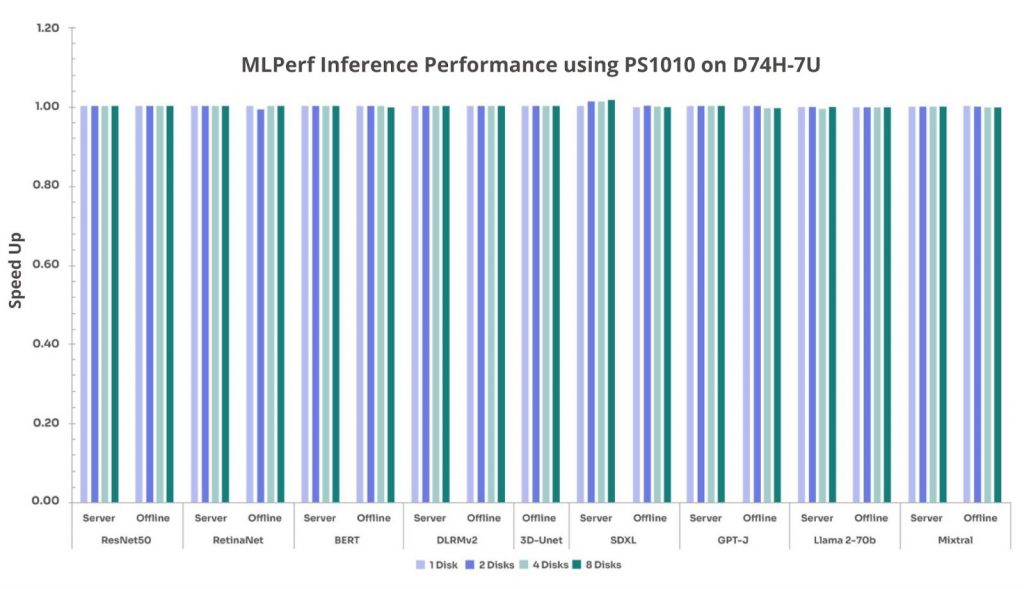
Figure 3. MLPerf inference with Solidigm D7-PS1010 on D74H-7U
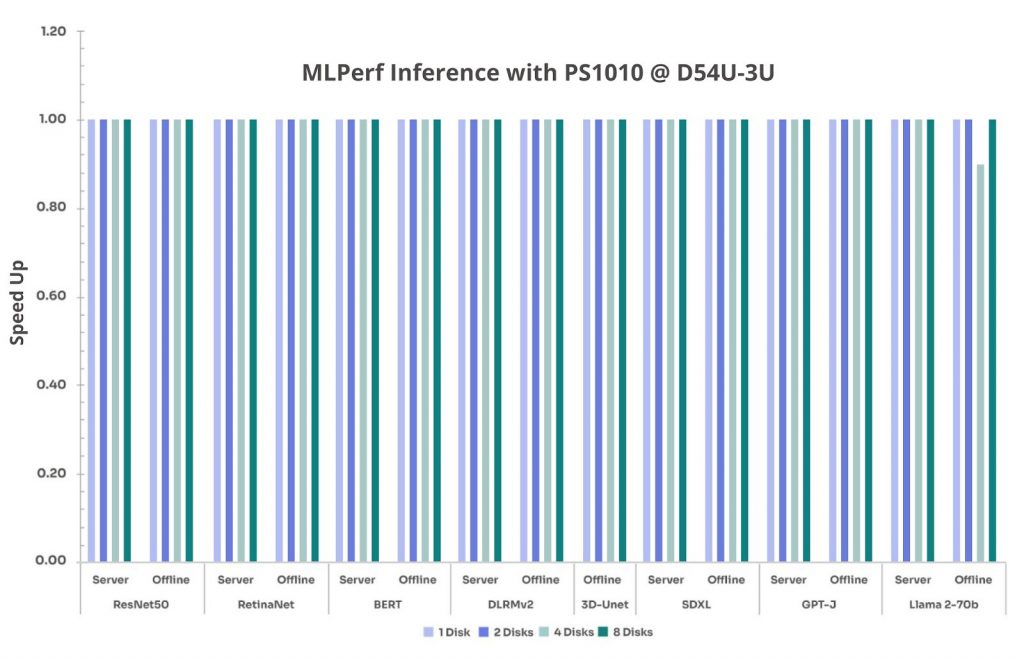
Figure 4: MLPerf inference with PS1010 on D54U-3U
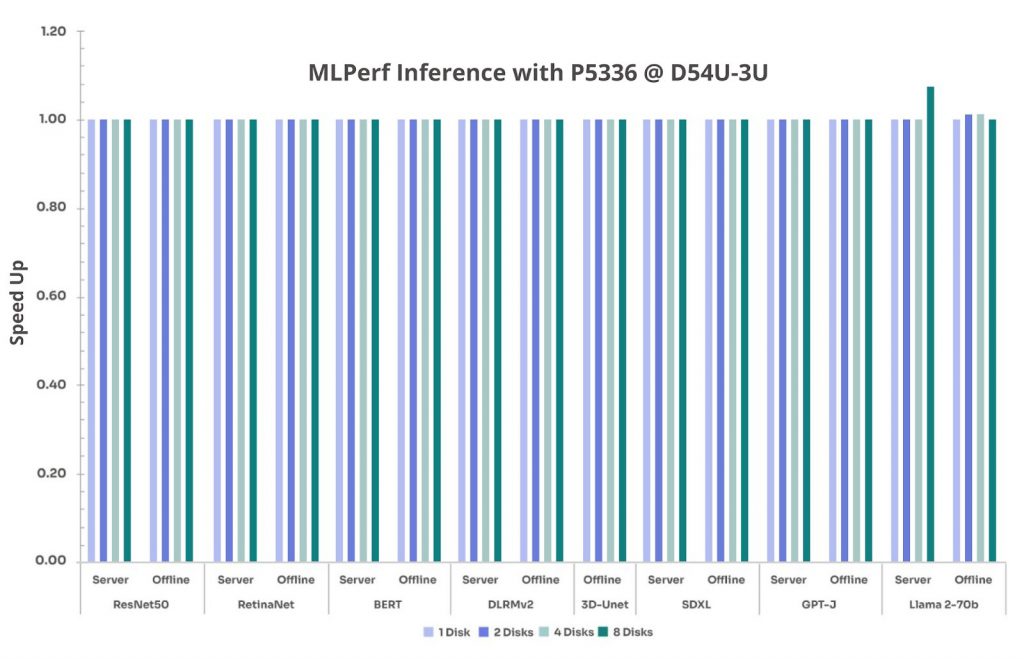
Figure 5 : MLPerf inference with P5336 on D54U-3U
Based on our MLPerf Inference measurements for this specific test configuration and workload profile, which are dominated by GPU and memory operations and use local SSDs for data access, we found that storage had only a minimal effect on inference performance across all benchmarks. Additionally, the trend remains consistent across the D74H-7U and D54U-3U platforms. This reinforces the importance of GPU and memory optimization over storage for real-time AI applications.
MLPerf Training v4.1
In contrast, training workloads, especially data-intensive models like DLRMv2, showed substantial performance improvements with high-speed NVMe SSDs. Key findings include:
- The D7-PS1010 (Gen5) outperformed the D5-P5336 in low-disk-count configurations. (Fig.6)
- Performance gains plateaued with scale, because the system had already eliminated storage as the bottleneck. Once storage was no longer the limiting factor, adding more SSDs produced diminishing returns.
- SATA SSDs (D3-S4520) were a bottleneck in our testing.
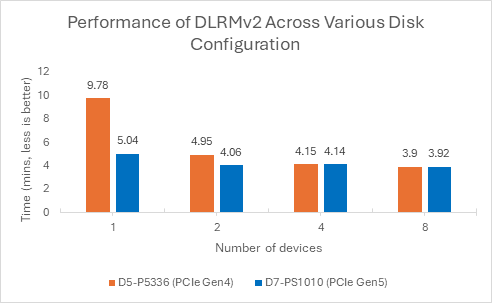
Figure 6: DLRMv2 performance across disk configuration
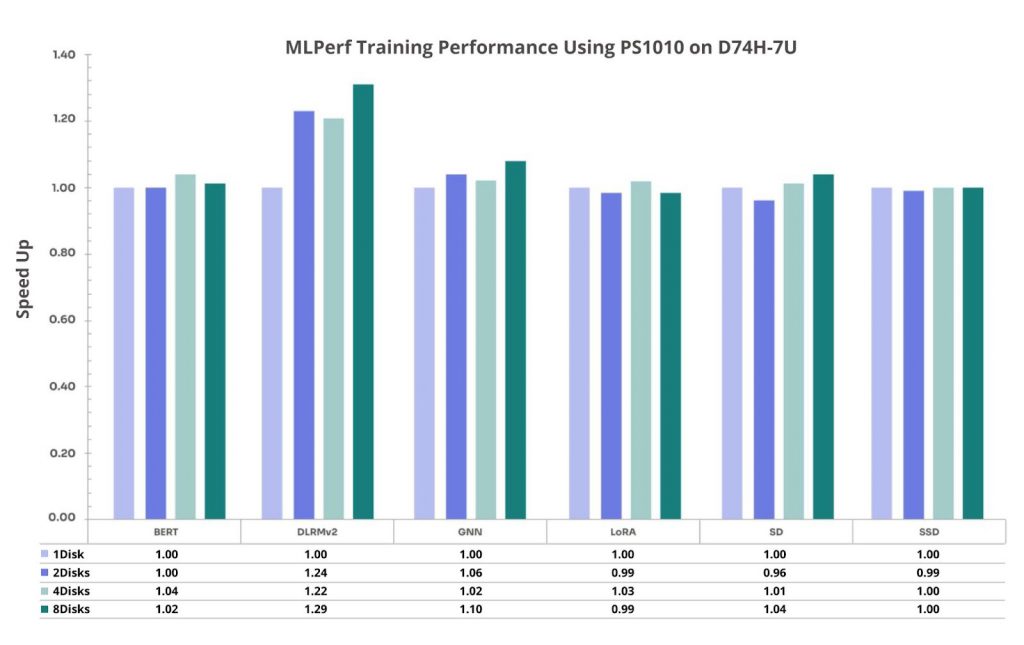
Figure 7. MLPerf Training with Solidigm D7-PS1010 on D74H-7U
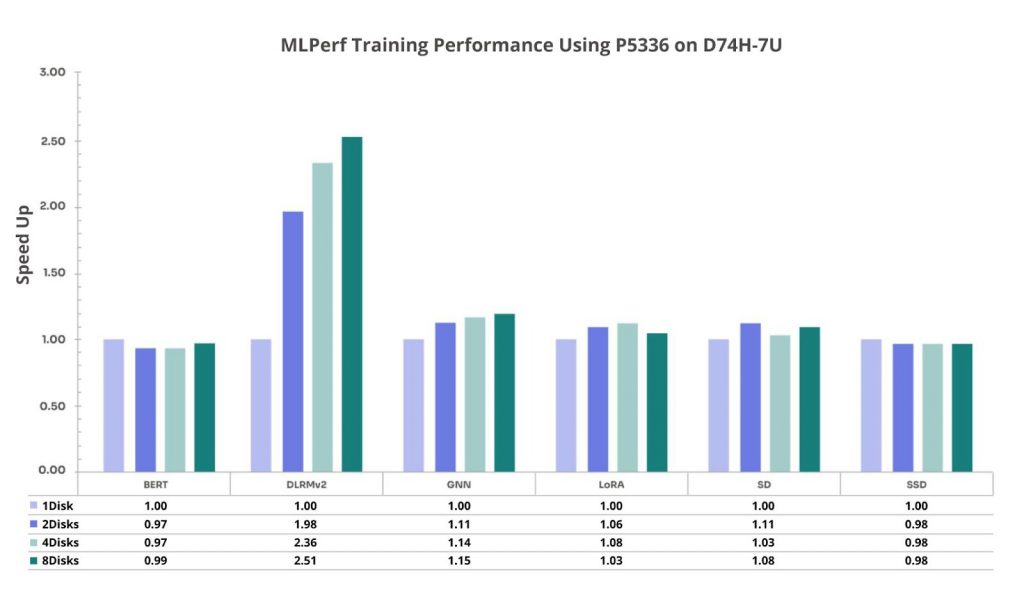
Figure 8. MLPerf Training with Solidigm D5-P5336 on D74H-7U
This highlights that for certain workloads and disk-count-dependent choices—leveraging Gen5 NVMe can be beneficial.
MLPerf Storage v2.0
The MLPerf Storage benchmark simulates three AI training workloads on a GPU, primarily testing the SSDs’ read performance. 3D U-net benefits significantly from increased drive count while ResNet-50 follows a similar trend that peaks around 4 drives. CosmoFlow however demonstrated minimal gains beyond 2 drives based on the plotted data, indicating its storage access patterns do not fully exploit additional NVMe devices. But overall, the results demonstrated that disk performance scales differently across workloads, emphasizing the importance of understanding workload-specific storage needs.
The test results of the SATA SSD (D3-S4520) were not competitive in our evaluation, making U.2 NVMe the only viable option.
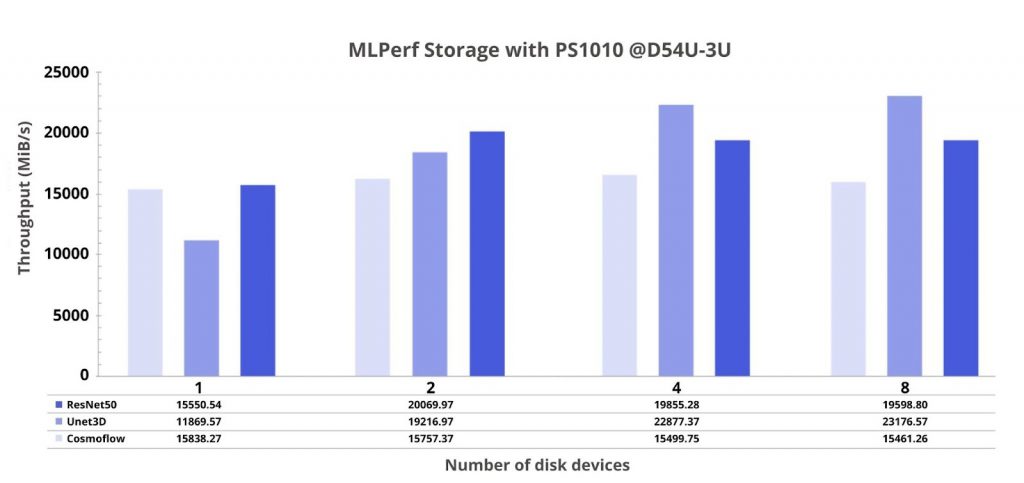
Figure 9. MLPerf Storage with D7-PS1010 on D54U-3U
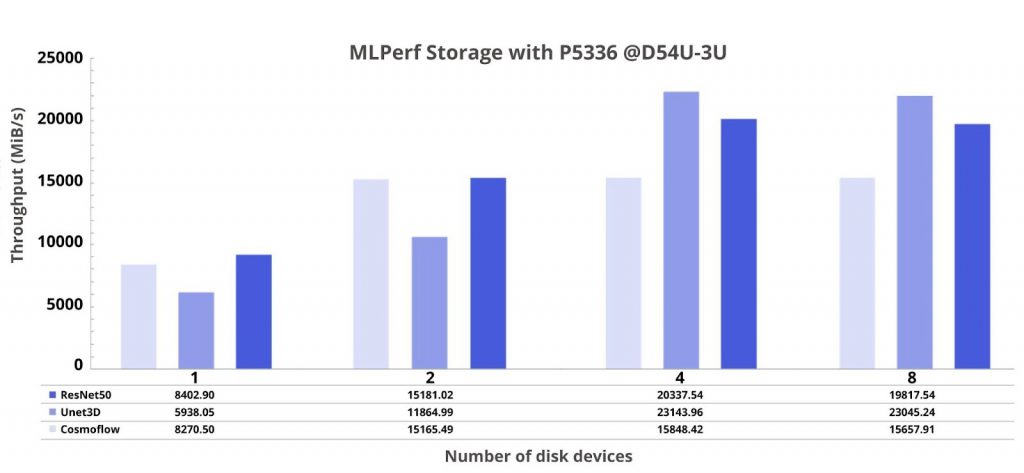
Figure 10. MLPerf Storage with D5-P5336 on D54U-3U
The MLPerf Storage benchmark further validated NVMe’s superiority:
- D7-PS1010 achieved peak throughput with fewer SSDs; it can reduce power and space requirements.
- D5-P5336 offered strong performance at scale, ideal for cost-sensitive, high-capacity deployments.
- D3-S4520 lagged significantly, underscoring the limitations of SATA in AI environments.
Conclusion
For these tests, QCT worked with Solidigm to reinforce the validity of AI efficiency by using different types of Solidigm storage options with QCT AI infrastructures. As a result, AI efficiency isn’t just about faster GPUs—it’s about achieving the right balance and understanding the strengths of different storage options to find and select better solutions for specific AI needs. For the MLPerf tested workloads, one can conclude there are benefits to investing in high-performance NVMe storage aligned with hardware choices and workload requirements. However, for training and inference, prioritizing compute and memory resources should have a higher priority over storage due to diminishing returns. For more information on the latest MLPerf Storage results visit here: https://mlcommons.org/benchmarks/storage/